actaim2-eccv24
Modes of interaction learning for unsupervised affordance discovery
Problem Statement
In the realm of object manipulation, human engagement typically manifests through a constrained array of discrete maneuvers. This interaction can often characterized by a handful of low-dimensional latent actions, such as the act of opening and closing a drawer. Notice that such interaction could diverge on different types of objects but the interaction mode such as opening and closing is discrete. In this paper, we explore how the learned prior emulates this limited repertoire of interactions and if such a prior can be learned from unsupervised play data. we take a perspective that decomposes the policy into two distinct components: a mode selector and a low-level action predictor, where the mode selector operates within a discretely structured latent space.
We introduce ActAIM2, which given an RGBD image of an articulated object and a robot, identifies meaningful interaction modes like opening drawer and closing drawer. ActAIM2 represents the interaction modes as discrete clusters of embedding. ActAIM2 then trains a policy that takes cluster embedding as input and produces control actions for the corresponding interactions.
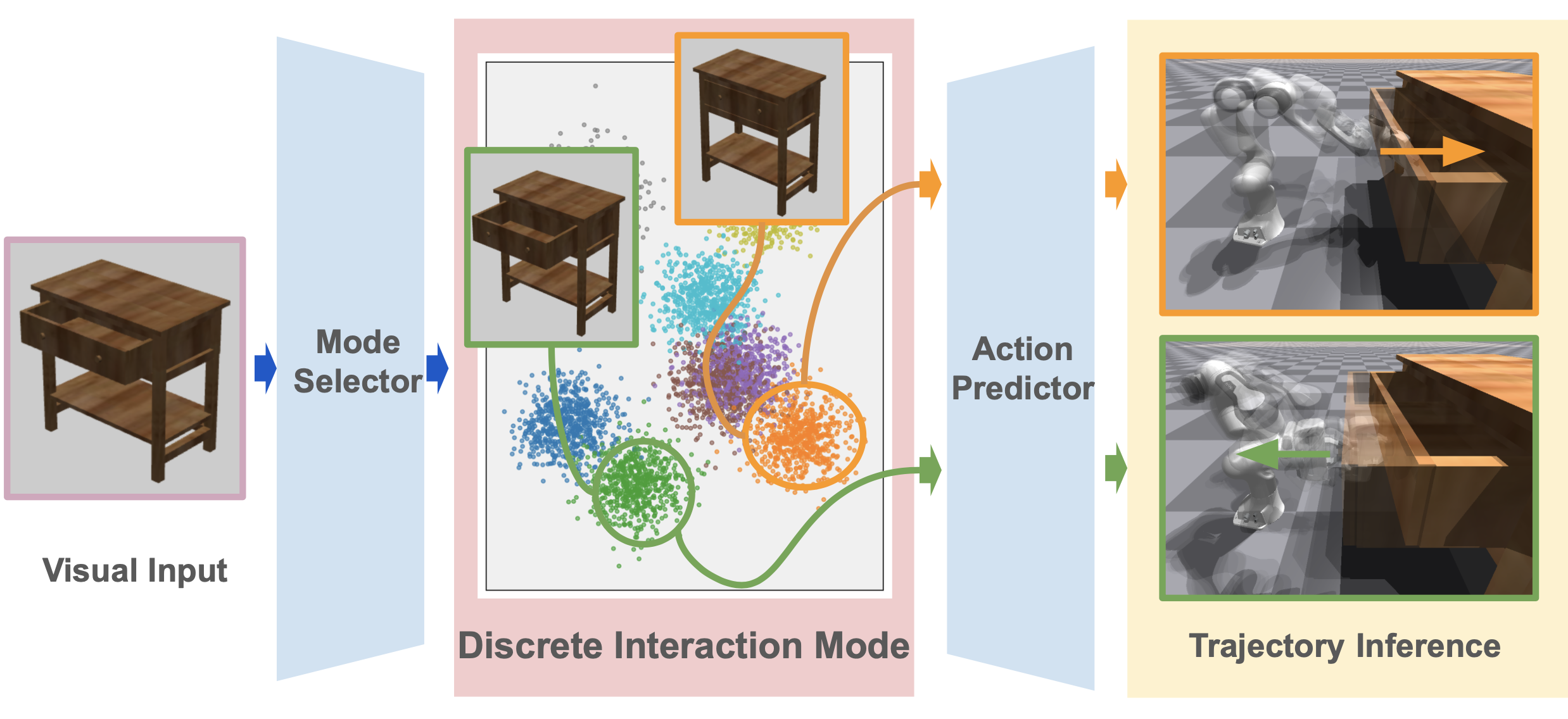
Problem Formulation
| Our model training aims to uncover the policy’s distribution $\mathbb{P}(a | o)$, with $o$ representing the observation and $a=(\mathbf{p}, \mathbf{R}, \mathbf{q})$ the action, through a decomposition strategy that reconfigures the action distribution as: |

Data Generation
Our dataset was constructed through a combination of random sampling, heuristic grasp sampling, and Gaussian Mixture Model (GMM)-based adaptive sampling, featuring the Franka Emika robot engaging with various articulated objects across multiple interaction modes.
The figure below indicates how we achieve diverse interaction mode sampling by using GMM-based adaptive sampling.
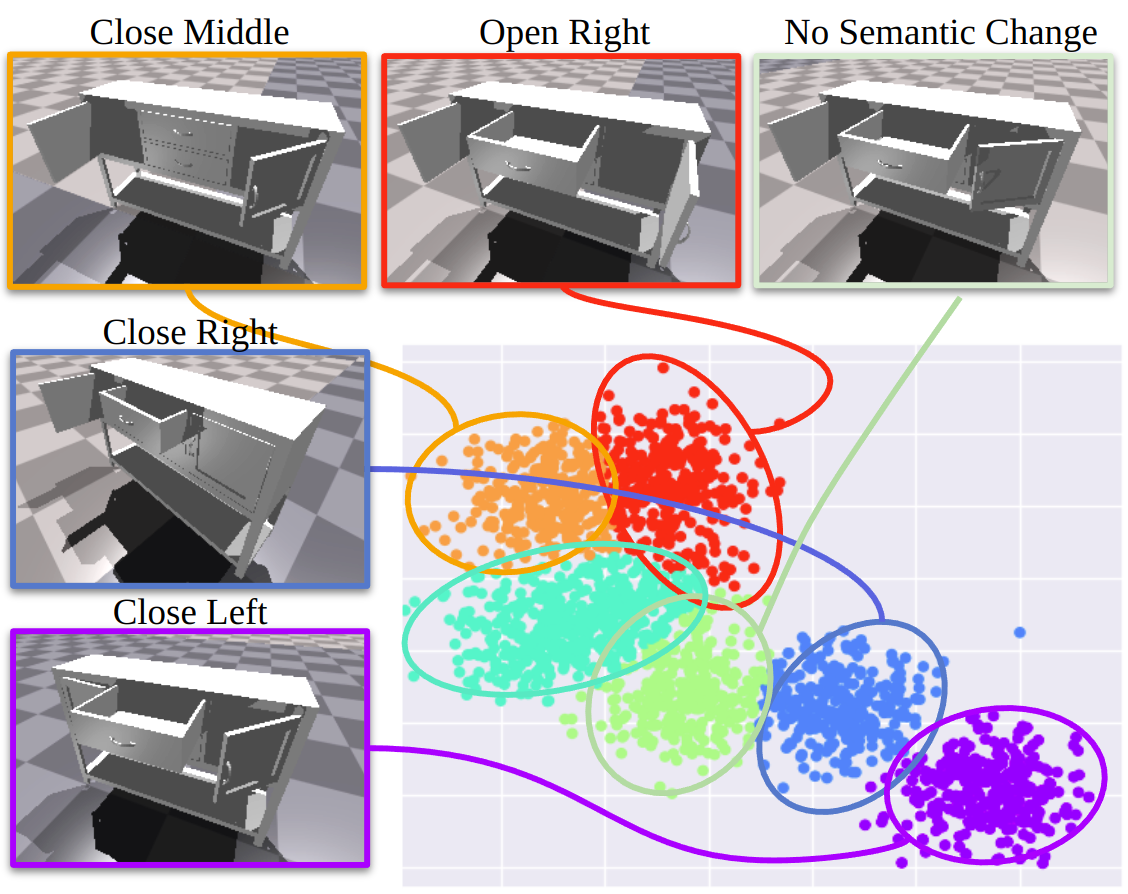
We also formulate our data collection algorithm here.

Unsupervised Mode Selector Learning
In this part, we show how we train and infer from the mode selector to extract the discrete task embedding for action predictor training. Our mode selector is a VAE-style generative model but replacing the simple Gaussian with the Mixture of Gaussian.
Mode Selector Training Process
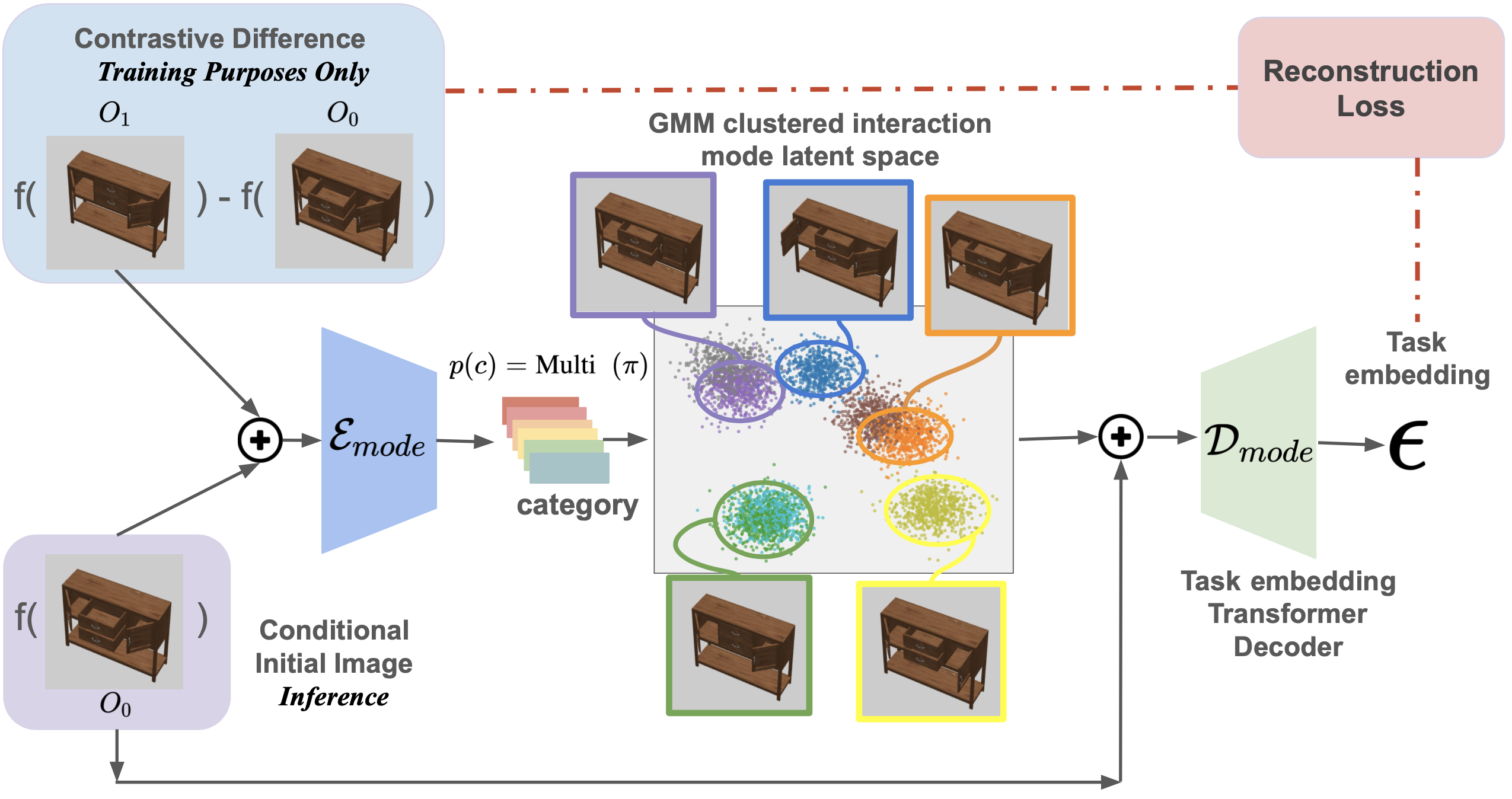
This figure illustrates the training procedure of the mode selector, mirroring the approach of a conditional generative model. It highlights the contrastive analysis between the initial and final observations—the latter serving as the ground truth for task embedding—to delineate generated data against the backdrop of encoded initial images as the conditional variable. The process involves inputting both the generated task embedding data and the conditional variable into a 4-layer Residual network-based mode encoder, which then predicts the categorical variable $c$. Following the Gaussian Mixture Variational Autoencoder (GMVAE) methodology, the Gaussian Mixture Model (GMM) variable $x$ is computed and introduced alongside the conditional variable to the task embedding transformer decoder. This model is tasked with predicting the reconstructed task embedding, sampled from the Gaussian distribution as outlined in the architecture of the mode selector decoder and calculating the reconstruction loss against the input ground truth data.
Mode Selector Inference Process
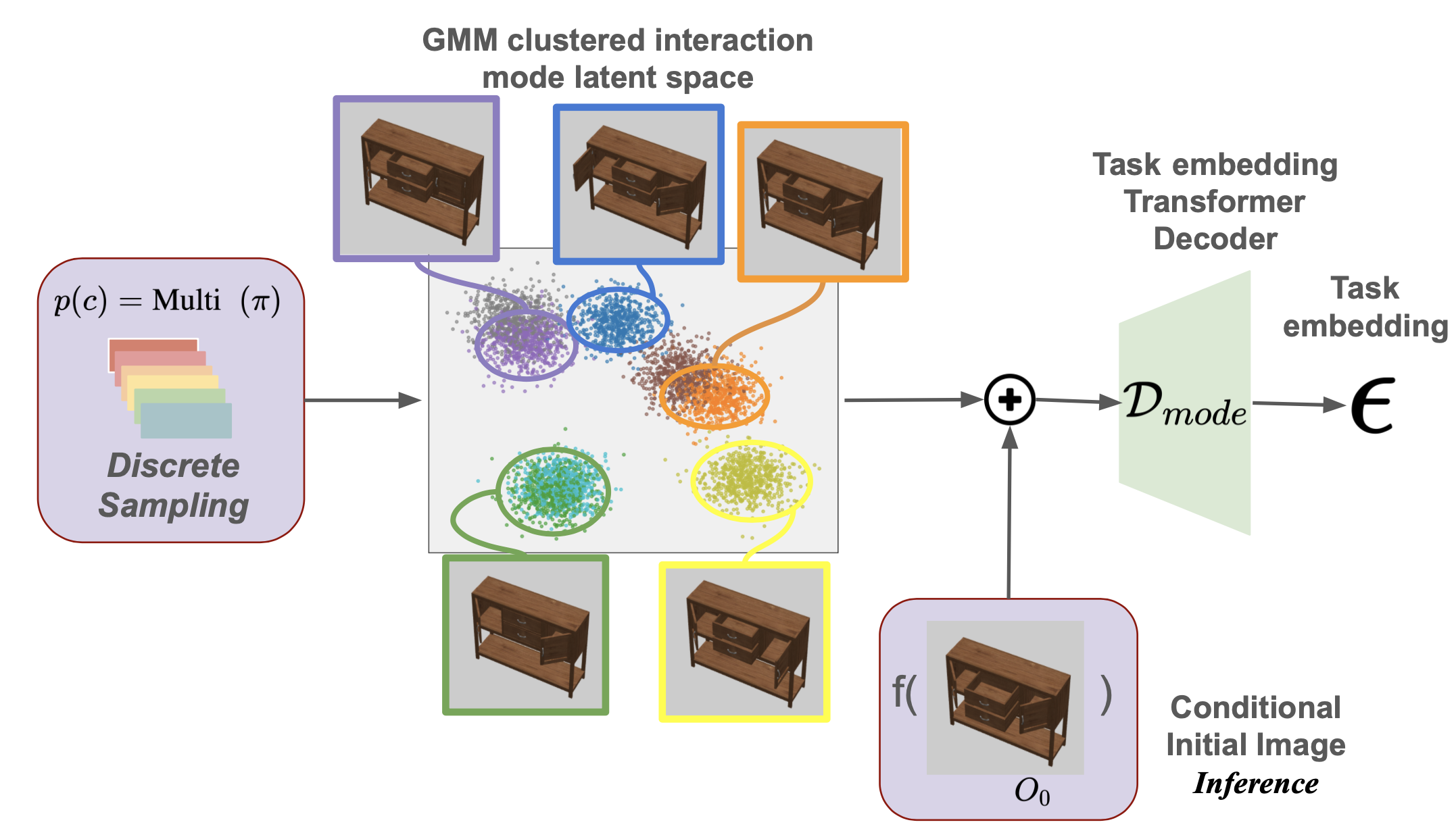
In the inference phase, the agent discretely samples a cluster from the trained Gaussian Mixture Variational Autoencoder (GMVAE) model to calculate the Mixture of Gaussian variable $x$. This variable $x$, in conjunction with the conditional variable (initial image observation), is then inputted into the mode selector transformer decoder. The objective is to reconstruct the task embedding for inference, effectively translating the conditional information and sampled cluster into actionable embeddings.
Mode Selector Qualitative Results
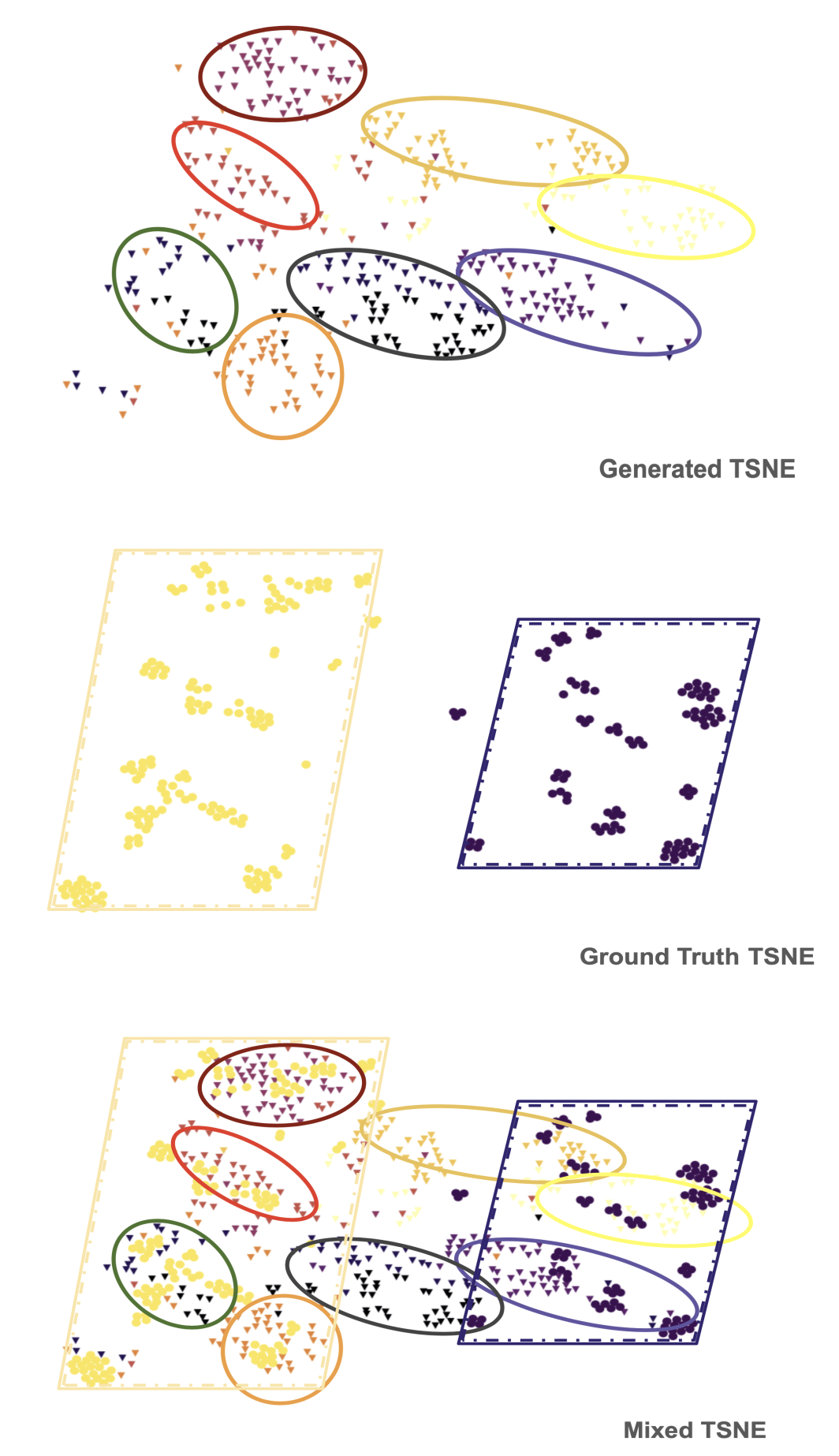
This disentanglement visualization with CGMVAE illustrates the efficacy of the Conditional Gaussian Mixture Variational Autoencoder (CGMVAE) in disentangling interaction modes for the “single drawer” object (ID: 20411), using a t-SNE plot for visualization. Task embeddings $\epsilon_j$, defined by the variance between initial and final object states, are visualized in distinct colors to denote various interaction modes and clusters. The sequence of figures demonstrates the CGMVAE’s precision in clustering and aligning data points with their respective interaction modes: (1) Generated clusters from the CGMVAE mode selector reveal distinct groupings. (2) Ground truth task embeddings confirm the model’s capacity for accurate interaction mode classification. (3) A combined visualization underscores the alignment between generated clusters and ground truth, showcasing the model’s ability to consistently categorize tasks within identical interaction modes.
Supervised Action Predictor Learning
Our objective is to infer a sequence of low-level actions $a=(\mathbf{p}, \mathbf{R}, \mathbf{q})$ from the current observation $O$ and task representation $\epsilon$, ensuring the action sequence effectively accomplishes the articulated object manipulation task while aligning with the constraints imposed by $\epsilon$.
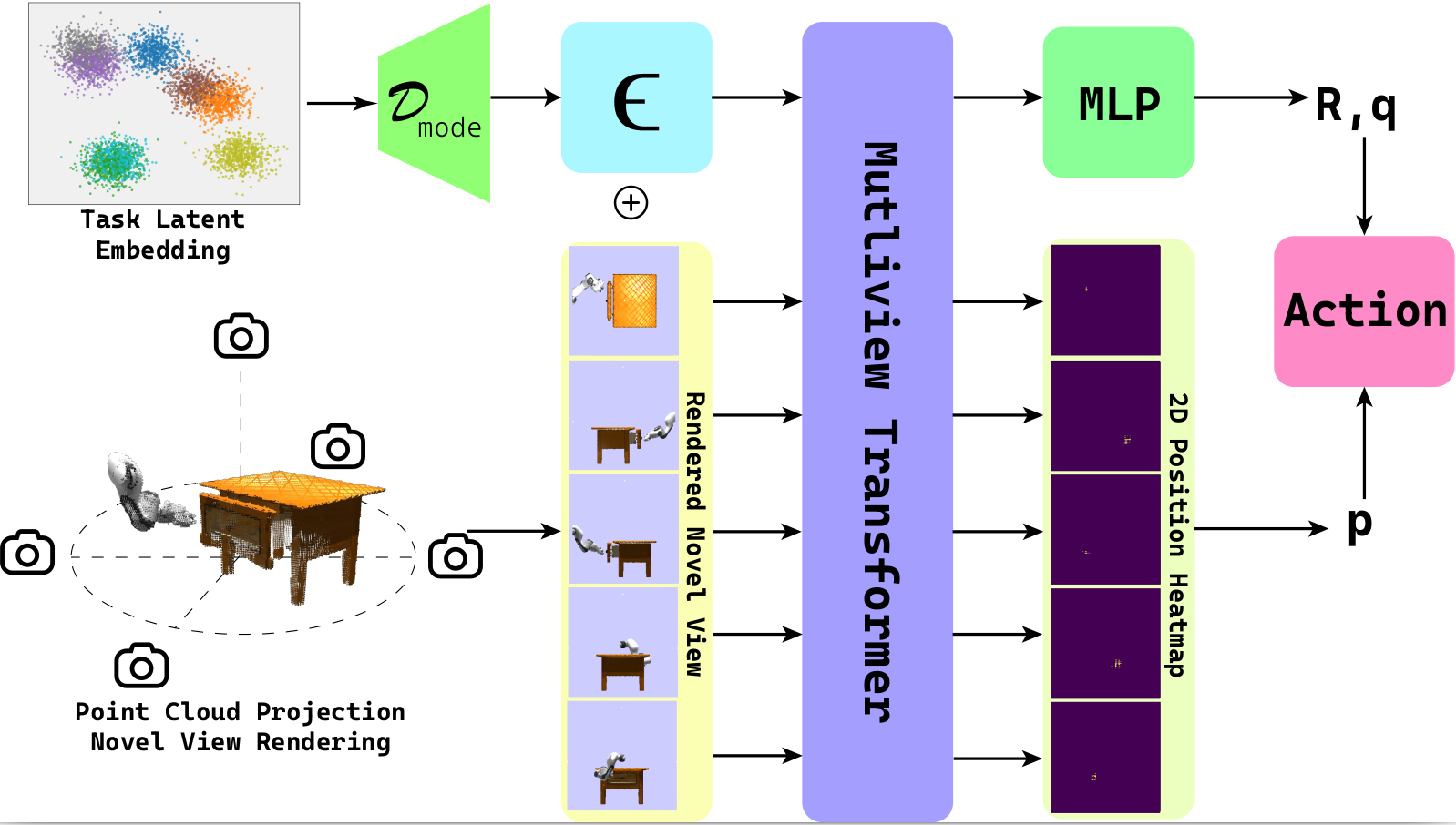
Interaction mode $\epsilon$ is sampled from latent space embedding from the model selector. Multiview RGBD observations are back-projected and fused into a color point cloud. Novel views are rendered by projecting the point cloud onto orthogonal image planes. Rendered image tokens and interaction mode tokens are contacted and fed through the multiview transformer. This output consists of global feature for rotation $\mathbf{R}$ and gripper state $\mathbf{q}$ estimation and 2D per-view heatmap for position $\mathbf{p}$ prediction.
Qualitative Results
Here, we provide more qualitative results about how our agent interacts with articulated objects in different interaction mode. We see how given different task embedding, action predictor produces actions representing distinct interaction modes. Here, we visualize the camera view and the prediction heatmap from the top for object instances. We also show the correspondent video of how our robot interacts with the object by extracting the gripper pose from the predicted heatmap.
Interacting with Faucet in 3 different interaction modes

Click the video here to see how the robot is interacting with the faucet above in 3 different interaction modes.
Interacting with a Table with multiple drawers in 3 different interaction modes
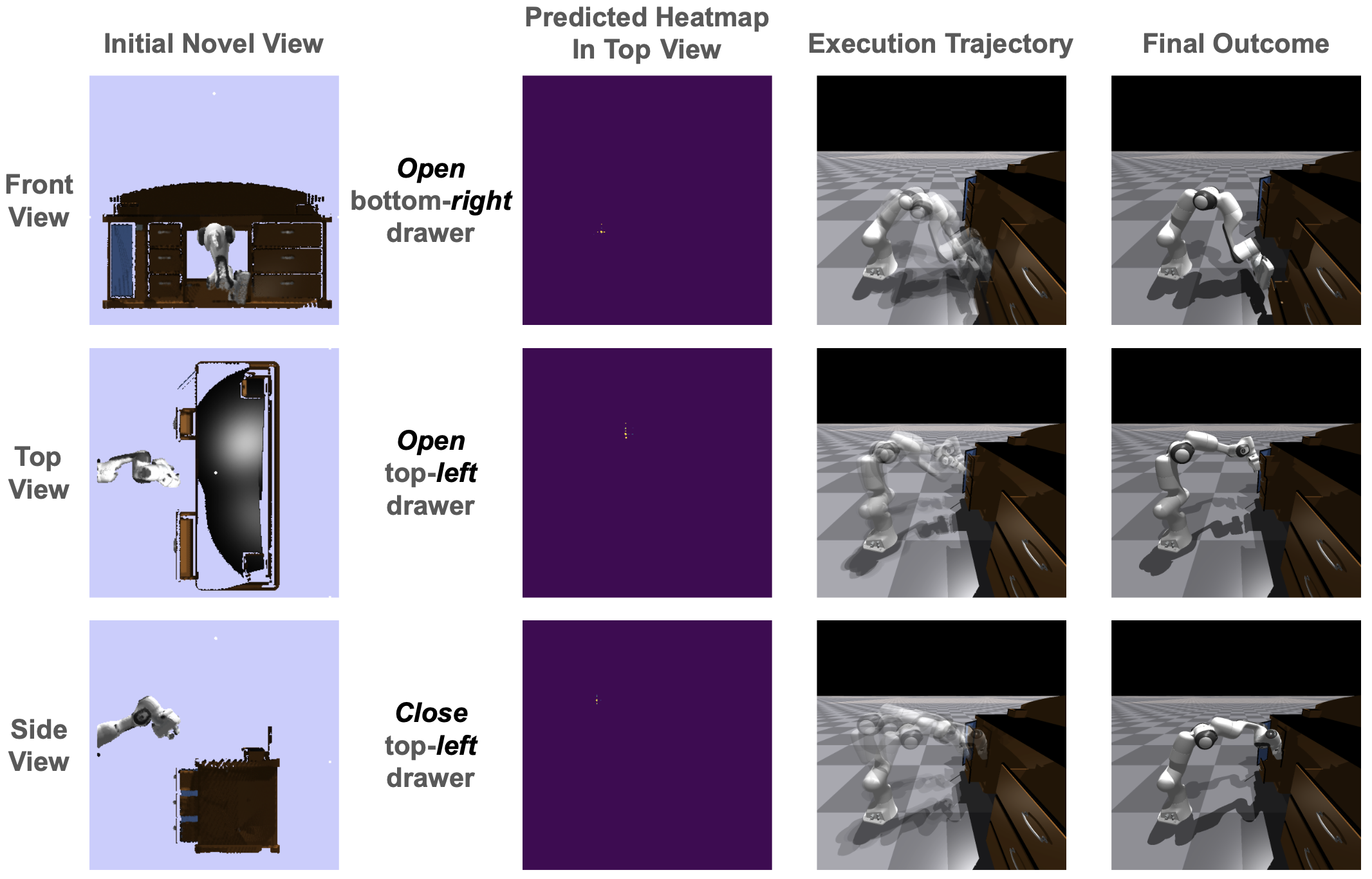
Click the video here to see how the robot is interacting with the table with multiple drawers above in 3 different interaction modes.
Interacting with a Table with multiple drawers in 3 different interaction modes
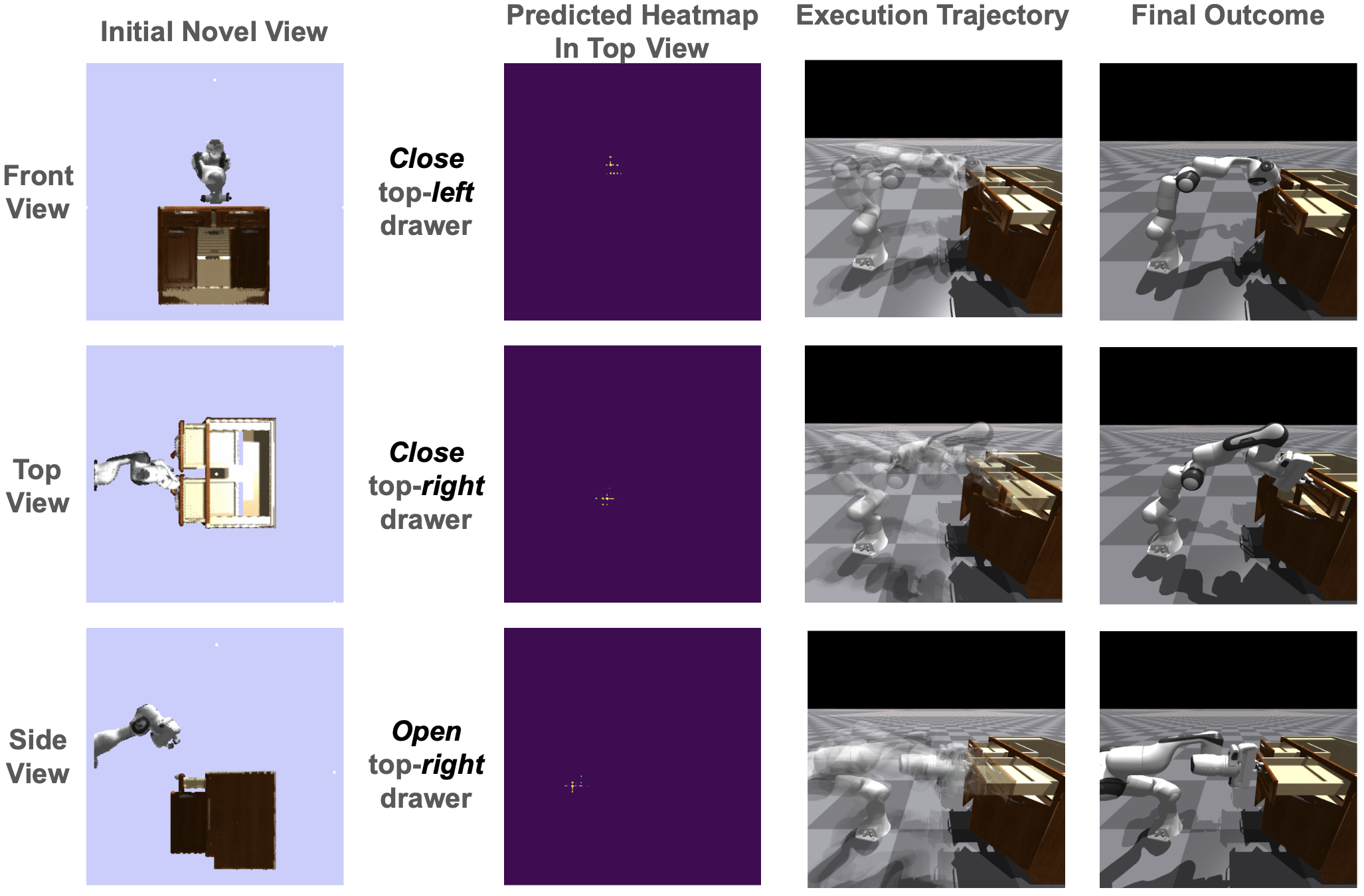
Click the video here to see how the robot is interacting with the table with multiple drawers above in 3 different interaction modes.
Here are more qualitative results of how the robot interacts with different types of articulated objects
Interacting with a switch and performing turning on and turning off
Interacting with a single drawer table and performing opening and closing the drawer
Interacting with a door and performing opening and closing on either side of the door